Classificações e Marco Teórico
1. Classificações e categorias teóricas
A classificação dos dados se dá quando o pesquisador insere conceitos capazes de promover uma segmentação dos fenômenos em diferentes classes, que precisam ser tratadas de forma independente para que a explicação faça sentido.
Por exemplo, podemos analisar as ADIs em busca de compreender os padrões de ajuizamento desse tipo de ação, um desafio que foi enfrentado no artigo Evolução do perfil dos demandantes no controle concentrado de constitucionalidade realizado pelo STF por meio de ADIs e ADPFs.
Esse tipo de investigação exigia que fizéssemos um levantamento dos Requerentes que ajuizaram as ADIs e ADPFs, o que nos leva a uma lista bastante heterogênea, com mais de 800 atores, que ajuizaram mais de 6000 processos. Na média, cada ator tinha ajuizado cerca de 8 ações, mas essa média não quer dizer rigorosamente nada porque havia uma grande concentração das ações em alguns poucos atores: os vinte demandantes com mais ações tinham ajuizado mais de metade dos processos:

Por outro lado, mais de 500 demandantes haviam ingressado apenas com 1 ação e 90 demandantes haviam ajuizados apenas 2 ações. Essa grande dispersão faz com que a maior parte dos trabalhos que tentaram entender os padrões de ajuizamento não tenha se concentrado nos agentes individuais que moveram as ações, mas nos tipos de agentes com legitimidade para mover tais ações, especialmente : governadores, partidos políticos, entidades de classe, MP e OAB.
Para reduzir essa multiplicidade de atores a certas classes, precisamos criar categorias que viabilizem essa subdivisão, que correspondem aos tipos citados acima. Cada categoria tem uma certa definição semântica (que diz o que ela significa) e aponta para um certo conjunto de objetos, mais ou menos heterogêneos.
Uma categoria curiosa, que costuma aparecer em nossas classificações, é outros. Nesse caso, podemos usar outros para designar todos os objetos que não entram na categorias que definem as pessoas com legitimidade para mobilizar o controle concentrado, e que podem entrar na classificação outros: pessoas físicas, diretórios regionais de partidos políticos, entidades nacionais que não são de classe, entidades de classe regionais, etc.
Quando fazemos essa união de certos objetos em determinados grupos de objetos, podemos gerar a possibilidade de fazer interpretações interessantes, desde que o critério de agrupamento seja relevante. A experiência nos sugere que é possível fazer afirmações interessantes sobre a atuação dos partidos políticos em geral, e não apenas de cada partido, em particular.
Quando não contávamos com os programas atuais de computação, essa classificação costumava ser feita pela definição de um sistema de códigos, que inclusive foi utilizado no banco de dados do referido artigo. Os governadores foram codificados como "5", o presidente foi codificado como "1", os partidos políticos como "8". A atribuição de um código numérico é uma maneira que agiliza muito o trabalho quando fazemos essas classificações de forma manual e a capacidade reduzida dos primeiros programas de computador utilizados para essa finalidade também exigia a criação de sistemas de códigos. Por esse motivo, falamos em codificação, para tratar desses sistemas de classificação.
Hoje, não precisamos usar códigos, pois podemos trabalhar sem problema com as classes a que esses códigos se referem. Porém, a utilização de códigos pode ser uma estratégia classificadora interessante, especialmente quando tratamos de múltiplos níveis de classificação simultâneo. Esse é o caso da classificação dos atos impugnados, cujos códigos indicam simultaneamente a distinção de órgão federativo (Federal, Estadual, Municipal) e do tipo de ato (Leis, Medidas Provisórias, Atos do Judiciário, etc.).
Explicando os conceitos ligados à classificação
A depender do enfoque adotado, daremos nomes diferentes aos elementos que compõem um sistema de classificação. Na pesquisa empírica, normalmente nos encontramos frente ao desafio de fazer afirmações sobre um universo, que é uma determinada população de objetos ou de pessoas.
Uma tabela tenta resumir um universo, composto por uma série de unidades, que serão descritas em cada linha. Contar o número de linhas nos mostra o tamanho da população (no caso de pesquisas censitárias) ou da amostra. É comum chamar cada uma desses elementos de objeto, para indicar claramente que se trata de uma das unidades da população (universo).
Cada uma das categorias usadas para descrever o objeto aparece em uma coluna e essas colunas são chamadas de variáveis (para indicar que elas variam conforme o objeto), ou de atributos (para designar que elas são qualidades atribuídas aos objetos). Essas variáveis/atributos são categorias utilizadas para a classificação dos objetos, e cada uma dessas categorias aponta para um certo conjunto possível de valores.
Numa classificação, os valores são as várias classes usadas para classificar os objetos, com relação a um determinado atributo. Por exemplo, tomando o objeto processo, podemos identificar para cada um deles o atributo tipo de demandante, sendo que esse atributo assume um valor para cada processo (uma das classes de demandantes, como Governador ou Presidente da República).
Classificações e Marco Teórico
Buscar explicações totalizantes para fenômenos diferentes termina nos levando a becos sem saída, em que não somos capazes de visualizar padrão algum ou no qual identificamos padrões equivocados. A atuação de um conjunto de 800 atores dificilmente pode ser explicada por um padrão unificado. Cada ator tem uma agenda diferente, um número de processos ajuizados, uma disponibilidade econômica e uma influência política diversas.
Podemos fazer um estudo de caso para entender a atuação individual de cada um, em um período, mas isso não nos fala nada sobre uma população, o que pode gerar conhecimentos de caráter mais geral. Para sair dos limites do caso específico, sem cair nas armadilhas de uma generalização sem sentido, a saída mais viável é a elaboração de um sistema de classificações que permita que tratemos, com sentido, da atuação de certos grupos de atores.
Essa classificação permite que façamos uma diferenciação adequada entre grupos de fenômenos que podem ser tratados como conjuntos, evitando os erros de uma generalização indevida, mas possibilitando fazer afirmações com certo grau de generalidade. Colocado assim o problema, creio que deve ficar claro o motivo pelo qual a classificação é sempre um desafio: ela implica sempre uma distorção dos objetos descritos.
A classificação é sempre uma escolha, uma proposta de segmentação da realidade em conjuntos de objetos. Ela define um nível de análise, um modelo descritivo que não é verdadeiro nem é falso, pois as classificações não correspondem ao mundo, elas organizam o mundo na forma de categorias conceituais.
Que classificações devem ser usadas? Essa é uma escolha teórica fundamental. Não se trata de um problema empírico, mas da definição das categorias a partir das quais os dados acerca do mundo empírico serão utilizados pelo pesquisador para construir modelos descritivos e explicativos.
Quando não conhecemos suficientemente as teorias existentes, podemos não ter uma noção clara dos diferentes sistemas de classificação disponíveis. Quando o conhecimento teórico é pequeno, o pesquisador pode até criar a ilusão de que somente existe apenas uma classificação correta, que é aquela que lhe é familiar.
No campo do direito, essa tendência é especialmente forte porque a formação dos juristas se dá pelo discurso dogmático, que normalmente apresenta uma certa classificação como correta: tipos de ações, tipos de contratos, tipos de efeitos da sentença, tipos de distribuição. A dogmática nos oferece muitas tipologias (ou seja, sistemas de classificação) que são ligadas à busca de definir uma decisão correta e são essas tipologias que são normalmente utilizadas pelos tribunais nas suas próprias decisões.
Por constituírem a própria linguagem do judiciário, são as classificações dogmáticas que formam as estruturas dos bancos de dados dos tribunais. Essas categorias se tornam tão familiares aos juristas que nós podemos facilmente naturalizá-las, o que pode limitar nosso "horizonte de classificação" às teorias dogmáticas que são usadas no discurso judicial.
Um exemplo de como isso ocorre é dado pela distinção dogmática procedência/improcedência. Essa é uma classificação ligada ao deferimento ou não dos pedidos feitos pelos advogados, e parece nos dar uma divisão em três níveis:
- procedência total;
- procedência parcial;
- improcedência.
De fato, em termos da conexão da atividade advocatícia (pedir) e da judicial (decidir), é uma classificação interessante, e sua inserção no dispositivo da sentença ou acórdão indica ao advogado algo relevante para as partes, inclusive para a definição da sucumbência. Porém, quando tentamos compreender o significado da decisão para a sociedade e não para o pedido, essa categoria pode levar ao equívoco de pensar que:
- procedência total significa que as partes satisfizeram os seus interesses;
- procedência parcial significa que as partes satisfizeram parcialmente os seus interesses;
- improcedência significa que as partes não satisfizeram seus interesses.
Embora isso possa ocorrer em alguns casos, é uma armadilha analisar as ADIs com esse prisma, por vários motivos. O primeiro é o de que essa classificação supõe que o objetivo das partes é obter decisões de procedência, sem levar em conta que pode haver muitos interesses extra-processuais no ajuizamento de uma ação: conseguir chamar atenção de um tema na mídia, obter uma decisão liminar imediata (sendo irrelevante a procedência final, que virá anos depois), pressionar politicamente uma autoridade.
Quando as partes não movem a ação exclusivamente em busca de uma decisão de procedência, a devida compreensão do comportamento das partes exige sistemas de classificação que ultrapasse o binômio procedência/improcedência. Uma possibilidade, por exemplo, é classificar as decisões em satisfativas e não-satifativas, com relação aos interesses principais.
Uma das decisões mais complexas de se avaliar é a decisão de procedência que utiliza a técnica da interpretação conforme a constituição. Essa é uma forma de decidir que aparentemente satisfaz os interesses do Requerente (porque o pedido é entendido como procedente), mas que não exclui do ordenamento uma lei que foi considerada inconstitucional. Como o que se considera interpretação conforme varia de caso a caso, é preciso avaliar individualmente se o provimento do tribunal foi ou não satisfativo com relação ao interesse das partes, sendo possível identificar decisões de procedência não-satisfativas.
A procedência parcial também é um conceito fugidio, pois pode significar a obtenção dos principais interesses (o que tornaria a decisão satisfativa), mas a procedência pode ter sido dada em uma parcela pouco significante do pedido (o que a tornaria não-satisfativa).
Essa análise mais cuidadosa das tipologias dogmáticas pode revelar muitos problemas em sua utilização na pesquisa em direito. As categorias dogmáticas são bem adaptadas a organizar um discurso decisório, mas não são modeladas para organizar uma reflexão sobre o significado político das práticas judiciais ou quando se tenta compreender o comportamento judicial ou o comportamento das partes.
A formulação de classificações adequadas é provavelmente o ponto mais delicado das pesquisas qualitativas, e é também a sua principal interface com o referencial teórico, que é a fonte de várias classificações:
- tipos de processo,
- tipos de sentença,
- tipos de contratos,
- tipos de partes,
- tipos de interações.
Os tipos não existem empiricamente: eles são classificações linguísticas por meio das quais nós qualificamos os objetos estudados. Por serem construções linguísticas, esses tipos são parte integrantes das teorias, ou seja, dos modelos que usamos para descrever e explicar.
Uma pesquisa precisa usar sistemas de classificação adaptados a seus objetos e, por isso, é preciso que o pesquisador desenvolva um conhecimento das várias abordagens possíveis: quanto maior o conhecimento teórico, mais amplas se tornam as possibilidades de escolha. Quanto maior nossa limitação à dogmática, mais difícil será incluir novos sistemas de classificação, que podem nos fazer construir modelos diferentes das percepções do senso comum dos juristas.
Teorias diversas nos dão modos diferentes de classificar os objetos, de hierarquizar as preocupações, de estabelecer conexões causais. As teorias nos oferecem os modelos pelos quais convertemos as nossas observações empíricas em uma descrição significativa. Isso faz com que, por mais que as pesquisas nos coloquem diretamente em contato com as evidências, não podemos perder de vista que esse contato é mediado pelas categorias teóricas que conformam as nossas formas de ver o mundo.
2. Requisitos de uma classificação robusta
2.1 Confiabiliade
Toda classificação robusta precisa ter critérios de classificação que sejam confiáveis, ou seja, que sejam passíveis de gerar os mesmos resultados caso sejam aplicados par pessoas diferentes, em tempos diferentes (Epstein e King 2013).
Se fazemos uma pesquisa em que buscamos identificar a prevalência de certos assuntos nas decisões liminares concedidas pelo STJ, precisamos contar com uma tabela de classificação de assuntos que tenha critérios suficientemente precisos e claros, para que os resultados sejam confiáveis. Uma impessoalidade absoluta pode ser quimérica, mas a falta de explicação adequada dos critérios pode fazer com que pessoas diferentes façam classificações tão díspares que o resultado da classificação não seja confiável.
Na pesquisa "A quem interessa o controle de constitucionalidade?", buscamos desenvolver categorias que identificassem quem eram as pessoas beneficiadas pelas decisões de ADI julgadas pelo STF, mas o fato é que não conseguimos desenvolver um sistema confiável de classificação. Em alguns casos, essa apreciação era simples (como quando um grupo de servidores recebia benefícios salarias), mas em outros ela era tão imprecisa (quando um determinado benefício era anulado) que não conseguimos estabelecer um critério de classificação minimamente satisfatório. Isso fez com que a pergunta fundamental do trabalho não fosse respondida de forma direta.
Porém, devemos conceder que mesmo as classificações que usamos não eram totalmente confiáveis, porque nos baseamos em distinções conceituais que não são totalmente definidas. Nós buscamos classificar os fundamentos da decisão, mas em muitos casos esses fundamentos eram múltiplos, o que dificultava identificar um fundamento único. Além disso, havia decisões que declaravam a inconstitucionalidade de vários dispositivos, por motivos diferentes, o que impedia uma classificação totalmente consistente. Para completar, havia casos em que as próprias decisões não eram muito consistentes, como na aplicação do princípio da simetria.
Uma dificuldade especial é que esses critérios de classificação tinham grandes impactos quantitativos, visto que nossa interpretação da atuação do STF dependia da verificação da predominância de certos tipos de decisões. Com isso, toda imprecisão conceitual gerava uma classificação imprecisa, e esta gerava medidas que incorporavam o mesmo grau de imprecisão.
Toda classificação prática precisa enfrentar esses desafios e alcançar um alto grau de confiabilidade é um objetivo difícil, embora deva pautar os esforços da pesquisa. De toda forma, a pesquisa precisa ser transparente quanto às suas próprias limitações: cabe esclarecer os critérios que foram efetivamente utilizados, para que os leitores possam avaliar a solidez dos diagnósticos e das explicações.
2.2 Validade
Uma classificação pode ser confiável (no sentido de ser precisa o suficiente para se tornar repetível), mas conduzir a resultados inválidos. Uma dificuldade que localizamos nas pesquisas sobre controle concentrado foi a de que muitas delas buscam fazer inferências a partir de todos os casos de ADIs, sem levar em consideração que os padrões de ajuizamento e de julgamento de ações diretas contra atos estaduais (ADEs) são muito diferentes das ações contra atos federas (ADFs).
Isso faz com que a contagem do número de decisões de procedência em ADIs conduza a resultados confiáveis, mas inválidos, na medida em que a falta de distinção entre a impugnação de atos federais e estaduais torna essa contagem de decisões um dados sem muito sentido prático.
Outro exemplo de medida inválida, de corrente de classificações inválidas, seriam as tentativas de utilizar a ideologia dos presidentes que indicaram os ministros do STF como indicadores de suas preferências ideológicas pessoais. Nos EUA, é comum que o grupo dos ministros indicados pelo Partido Republicano sejam considerados como ideologicamente diversos do grupo dos ministros indicados pelo Partido Democrata. Porém, esse é um tipo de ligação muito tênue em nosso presidencialismo de coalização, o que faz com que a busca de aplicar no Brasil metodologias que diferenciam os ministros em termos da presidência que os nomeou tende a gerar resultados inválidos.
Dados estruturados e Dados não-estruturados
A classificação dos objetos gera dados que chamamos de "estruturados", pois eles se encontram organizados segundo uma estrutura, que define um certo objeto a partir de um conjunto determinado de variáveis que têm uma amplitude definida.
Embora seja comum ligar os dados estruturados com dados organizados em tabelas, o conteúdo de certos atributos pode ser composto por elementos que não constituem dados estruturados. Esse é, por exemplo, o caso de haver uma tabela de processos com uma coluna de ementa ou decisão.
Uma ementa ou um dispositivo, por exemplo, são blocos textuais que não têm uma estrutura definida. São trechos de linguagem natural, que demandam uma complexa interpretação para que sejam extraídos delas alguns dados estruturados, contidos em categorias mais específicas: tipo da decisão, data da decisão, unanimidade/maioria.
Embora haja certa ambiguidade nos termos, os textos em linguagem natural são considerados tipicamente dados não-estruturados, que desafiam as estratégias mais simples de agregação, como operações matemáticas (como médias) e operações de contagem (que se aplicam a variáveis com um range restrito de valores).
Os dados estruturados podem ser utilizados por esses tipos de operação, enquanto os dados não-estruturados precisam de processos de análise e interpretação que extraiam deles dados estruturados ou de processos específicos para lidar com esse tipo de informação, que envolvem estratégias de inteligência artificial.
Quando trabalhamos com a análise de processos judiciais, costumamos encontrar certos dados estruturados, que admitem valores dentro de um conjunto finito de possibilidades: data de ajuizamento, decisão final, tipo de requerente. Mas também encontramos dados não-estruturados e complexos, como ementas, decisões, votos e gravações.
Cada um desses elementos não-estruturados, composto por trechos de linguagem natural, pode ser a fonte de muitos dados relevantes, desde que sejam devidamente interpretados.
Dados e informações
Se você tiver uma lista com as ementas de todas as ADIs, o que esse conjunto de dados te diz? Como é possível transformar esse conjunto de dados dispersos em uma informação acerca da população de ementas?
É comum distinguir de dado (que é um objeto a ser interpretado) da informação, que é o resultado da interpretação dos dados. Nem sempre usamos essa diferença de forma muito precisa, inclusive porque informação é um conceito relacional: é sempre informação com relação a certo sistema.
Em uma tabela sobre processos, há uma série de atributos dos processos, que podem ser consideradas informações sobre os processos. Saber a ementa de um processo nos faz ter uma informação sobre ele. Assim, a data de autuação de um processo é uma informação com relação àquele processo, mas é um dado com relação à população de processos.
Quando você constitui uma base de dados voltada a permitir uma compreensão dos padrões de ajuizamento de ADIs ou de julgamentos de medidas cautelares, a data de autuação é apenas um dado. Para que seja possível fazer uma afirmação sobre o tempo de processamento das adis, é preciso ter muitos dados, que podem viabilizar uma interpretação que consolide a descrição na identificação de um tempo médio.
Parece-me mais proveitoso entender que a informação é um enunciado linguístico feito acerca de um objeto empírico, a partir de certas evidências, e chamamos de dados as evidências que nos permitem inferir uma informação.
Modelo de dados e marco teórico
Quando organizamos os dados em um modelo de dados, nós precisamos agrupá-los dentro de certas variáveis. Quando fazemos isso, geramos uma dinâmica entre objetos (unidades de análise), atributos (que é uma categoria) e valor (que é um dado), que nos oferece uma tabela.
Esses valores normalmente são de 4 tipos: sequências de caracteres (string), datas (no sentido geral de marcadores de tempo, o que pode envolver também horas), números integrais (int) e números fracionários (float).

Na tabela acima, cada linha corresponde a um objeto, que são os elementos de nossa unidade de análise. A primeira coluna corresponde ao nome do objeto, que é uma variável do tipo string que desempenha uma função particular: ela designa o modo pelo qual nos referimos ao objeto.
Se houver várias linhas para o mesmo objeto, teremos problemas para a analisar os dados, visto que os programas que usamos pressupõem que cada linha é um objeto diverso. Assim, duas linhas com o mesmo nome podem indicar objetos "homônimos", mas elas devem indicar ser dois objetos diferentes. Por isso, é necessário que desenvolvamos uma "string" que funcione como identificador, de modo que qualquer pesquisa feita com esse argumento nos conduza ao objeto desejado. Esse identificador costuma estar na primeira coluna.
Nas minhas tabelas sobre o STF, costumo usar como identificador a sigla da Classe + o número do processo, com 5 dígitos. Note que o indicador é também uma variável, com a peculiaridade que o seu "range" é o mesmo do número de objetos, pois deve haver um indicador por objeto.
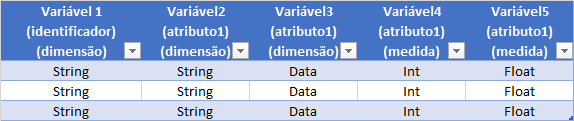
Quanto às demais variáveis, uma classificação importante é a distinção entre dimensões e medidas. Medidas são variáveis numéricas, sejam de números integrais (int) ou fracionários (float). Essa distinção é importante porque as variáveis numéricas podem ser usadas em operações matemáticas, e as dimensões não.
Tal distinção precisa ser feita especialmente quando usamos um sistema de de códigos numéricos, como feito na base de dados do artigo sobre o Perfil de Ajuizamento no Controle Concentrado, em que o tipo de requerente foi codificado a partir do inciso que confere legitimidade para o ajuizamento de ADIs e ADPFs. Todos os governadores foram codificados como "5", mas esse caractere não corresponde a uma medida (um número), mas sim a uma dimensão. Nesse caso, o valor contido na célula é "5", esse dígito opera como um "nome" e não como um "número".
Nas análises quantitativas, nós muitas vezes construímos medidas a partir de dimensões. Já fizemos isso nas tabelas dinâmicas e continuaremos realizando essa operação de contagem. Quando contamos o número de células com valores "Procedente", isso nos gera uma medida (a contagem), que nos permite fazer análises quantitativas (como descobrir a porcentagem de ADIs julgadas procedentes).
Para que a contagem nos ofereça dados úteis, é preciso que o "range" da variável seja pequeno. Quando a nossa classificação é binária (Julgado, Não-Julgado) ou tem poucos elementos elementos (por exemplo: Aguardando Julgamento, Procedente , Extinto Processualmente e Outros), nós conseguimos fazer gráficos que consolidem as informações de maneira bastante visível. Porém, quando fazemos um gráfico de todos os Requerentes, teremos mais de 400 valores, o que inviabiliza consolidar essas informações em um gráfico.
No caso de medidas, essa multiplicação de valores é resolvida por meio de operações que oferecem mensurações sobre a população (médias, medianas) ou por meio do agrupamento dos valores em quartis, por exemplo. No caso das dimensões, é preciso ter um grupo discreto de valores, o que exige de nós um esforço de classificação: agrupar as unidades a partir de critérios precisos, confiáveis e úteis.
A construção do modelo de dados (com a definição das unidades de análise, das variáveis que serão medidas ou classificadas, dos possíveis valores que essas variáveis podem adotar) é um elemento ligado ao marco teórico porque é esse referencial que oferece ao pesquisador a rede de categorias que será utilizada para definir os critérios pelos quais os seus dados serão organizados em um modelo, que será interpretado da forma definida na metodologia.
Portanto, uma parte relevante do referencial teórico é a explicitação dos sistemas conceituais que são utilizados para guiar a observação empírica e a organização dos dados, respondendo a questões como:
- o que é uma decisão e quais são os seus tipos;
- o que é um algoritmo e quais são os seus tipos;
- o que é uma ementa e quais são os seus tipos, seu objetivos, suas possíveis estruturas.
- o que é um smart contract e quais são os seus tipos.
Em suma: para que possam ser interpretados adequadamente, os dados precisam ser classificados. Sem um sistema de classificação, somos incapazes de segmentar os dados em grupos diferentes e identificar os padrões ligados a cada um desses grupos. A ausência de uma classificação (ou a presença de uma tipologia inadequada) impede a observação de padrões complexos dentro do universo analisado e é no estudo teórico que criamos um repertório de classificações possíveis.
